Markov Decision Process
오늘은 Markov Decision Process에 대해서 간략히 알아보겠습니다. Markov는 1800년대의 러시아 수학자의 이름입니다. 이 분의 이름이 하나의 형용사가 되었는데 그 의미는 다음과 같습니다.

뒤에서 state와 value에 대해서 설명하겠습니다.
위의 첫 식처럼 처음 어떠한 상태로부터 시작해서 현재 상태까지 올 확률이 바로 전 상태에서 현재 상태까지 올 확률과 같을 때, 두 번째 식처럼 표현이 될 수 있고 state는 Markov하다고 일컬어질 수 있습니다.
스타크래프트같은 게임이라고 생각하면 게임 중간 어떤 상황은 이전의 모든 상황들에 영향을 받아서 지금의 상황이 된 것이기 때문에 사실은 지금 상황에 이전 상황에 대한 정보들이 모두 담겨있다고 가정할수도 있습니다. 강화학습이 기본적으로 MDP로 정의되는 문제를 풀기때문에 state는 Markov라고 가정하고 접근합니다. 하지만 절대적인 것은 아니며 Non-Markovian MDP도 있으며 그러한 문제를 풀기위한 강화학습들도 있지만 상대적으로 연구가 덜 되었으며 처음에 접하기에는 적합하지 않습니다. 강화학습에서는 value라는 어떠한 가치가 현재의 state의 함수로 표현되고 이 state가 Markov하다고 가정됩니다.

위 그림에서 로봇이 세상을 바라보고 이해하는 방식이 MDP가 됩니다. MDP란 Markov Decision Process의 약자로서 state, action, state transition probability matrix, reward, discount factor로 이루어져있습니다. 로봇이 있는 위치가 state, 앞뒤좌우로 이동하는 것이 action, 저 멀리 보이는 빛나는 보석이 reward입니다. 한 마디로 문제의 정의입니다. 이제 이 로봇은 보석을 얻기 위해 어떻게 해야할지를 학습하게 될 것 입니다
State
간단히 설명을 하자면 state는 agent가 인식하는 자신의 상태입니다. 사람으로 치자면 눈이라는 관측도구를 통해서 “나는 방에 있어”라고 인식하는 과정에서 “방”이 state가 됩니다. 이 이외에도 state는 생각보다 많은 것들이 될 수 있는데 달리는 차 같은 경우에는 “차는 Jeep이고 사람은 4명 탔으며 현재 100km/h로 달리고 있다”라는 것이 state가 될 수 있습니다. OpenAI에도 있는 atari game같은 경우에는 게임화면 자체, 즉 pixel이 agent가 인식하는 state가 됩니다. 또 Cartpole에서는 cart의 x위치와 속도, pole의 각도와 각속도가 state가 됩니다. 즉, 문제는 정의하기 나름입니다. 실재로 어떠한 문제를 강화학습으로 풀 수도 있고 다른 machine learning 기법으로 풀 수도 있기 때문에 강화학습을 적용시키기 전에 왜 강화학습을 써야하고 다른 머신러닝 기법에 비해서 나은 점이 무엇인가를 따져보고 사용해야할 것 같습니다. 강화학습은 “시간”이라는 개념이 있는 문제를 푸는 인공지능 기법입니다. 이는 결국 강화학습의 목표가 Policy(일련의 행동들)된다는 의미를 함포합니다.
Action
Agent의 역할은 무엇일까요? environment에서 특정 state에 갔을 때 action을 지시하는 것입니다. robot이 왼쪽으로 갈지, 오른쪽으로 갈 지를 결정해주는 역할입니다. 그래서 사람의 뇌라고 생각하면 이해가 쉽습니다. “오른쪽으로 간다”, “왼쪽으로 간다”라는 것이 action이 되고 agent가 그 action를 취했을 경우에 실재로 오른쪽이나 왼쪽으로 움직이게 됩니다. 또한 agent는 action을 취함으로서 자신의 state를 변화시킬 수 있습니다. 로봇에서는 흔히 Controller라 부르는 개념입니다.
Reward
agent가 action을 취하면 그에 따른 reward를 “environment”가 agent에게 알려줍니다. 그 reward는 atari game에서는 “score”, 바둑의 경우에는 승패( 알파고가 학습하는 방법), trajectory control의 경우에는 “의도한 궤도에 얼마나 가깝게 움직였나”가 됩니다. 정의는 다음과 같습니다. s라는 state에 있을 때 a라는 action을 취했을 때 얻을 수 있는 reward입니다. 강화학습에서는 정답이나 사전에 환경에 대한 지식이 없이 이 reward를 통해서 agent가 학습하게 됩니다. 이 reward를 immediate reward라고 하는데 agent는 단순히 즉각적으로 나오는 reward만 보는 것이 아니라 이후로 얻는 reward들까지 고려합니다.
Agent-Environment Interface
이렇듯 agent는 action을 취하고 state를 옮기고 reward를 받고 하면서 environment와 상호작용을 하는데
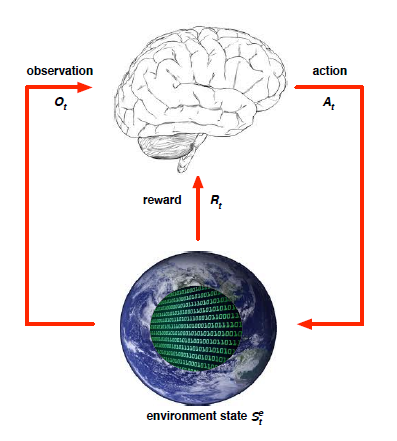
agent가 observation을 통해서 자신의 state를 알게되면 그 state에 맞는 action을 취하게 됩니다. 학습을 하지 않은 초기에는 random action을 취합니다. 그러면 environment가 agent에게 reward와 다음 state를 알려주게 됩니다. 시뮬레이터나 게임이 environment가 될 수도 있고 실재 세상이 environment가 될 수도 있습니다.
지금까지 강화학습의 기초 개념들에 대해서 알아보았습니다. 강화학습은 상당히 복잡하여 앞으로 배워야할 개념들이 많지만 오늘 포스팅한 Action, Reward, State의 개념들은 반드시 알아두시면 좋을듯합니다.